
Uso de redes neuronales recurrentes en bioinformática
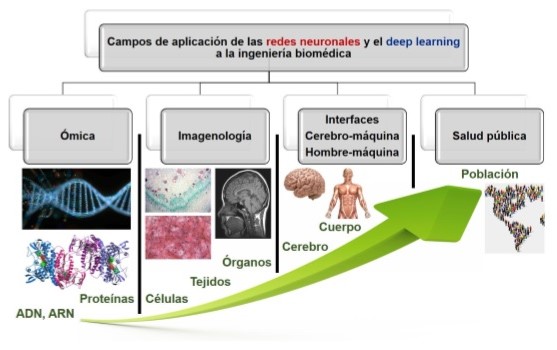
Las redes neuronales recurrentes (RNN) han transformado el panorama de la bioinformática, un campo que combina biología, informática y matemáticas para abordar problemas complejos relacionados con datos biológicos. Estas redes, que son especialmente efectivas para procesar y predecir secuencias, han encontrado múltiples aplicaciones, desde el análisis de secuencias de ADN hasta la predicción de estructuras de proteínas. Con su capacidad para manejar información temporal y secuencial, las RNN ofrecen herramientas poderosas para profundizar en la comprensión de procesos biológicos y desarrollar nuevas tecnologías en campos como la medicina personalizada.
En este artículo, exploraremos en profundidad el uso de redes neuronales recurrentes en bioinformática, examinando sus principios fundamentales, así como sus aplicaciones prácticas y el impacto que han tenido en el análisis de datos biológicos. Comenzaremos por discutir qué son las RNN y cómo funcionan, para luego abordar sus aplicaciones específicas en la bioinformática y concluir con algunas reflexiones sobre su futuro en este campo emergente.
Índice
- ¿Qué son las redes neuronales recurrentes?
- Principios de funcionamiento de las RNN en bioinformática
- Aplicaciones de las redes neuronales recurrentes en bioinformática
- Beneficios de utilizar RNN en bioinformática
- Desafíos y limitaciones de las RNN en bioinformática
- El futuro de las RNN en bioinformática
- Conclusión
¿Qué son las redes neuronales recurrentes?
Las redes neuronales recurrentes son un tipo de arquitectura de red neuronal diseñada para procesar datos secuenciales. A diferencia de las redes neuronales tradicionales, que solo consideran la información de entrada en el momento presente, las RNN tienen la capacidad de mantener información en su memoria a lo largo del tiempo. Esta propiedad es especialmente útil para tareas donde las dependencias temporales son críticas, como el reconocimiento de voz, la traducción automática y, por supuesto, el análisis de datos biológicos.
La estructura de las RNN les permite tener conexiones de retroalimentación, lo que significa que la salida de una neurona puede influir en la entrada de la misma neurona en un momento posterior. Esta característica única las hace ideales para manejar secuencias de datos, ya que pueden recordar información previa y usarla en cálculos futuros. Por ejemplo, en el contexto de la bioinformática, una RNN puede procesar una secuencia de nucleótidos en el ADN y utilizar la información de bases anteriores para predecir la probabilidad de una mutación futura o el impacto de una variante genética.
Principios de funcionamiento de las RNN en bioinformática
El funcionamiento de las RNN en bioinformática se basa en varios principios matemáticos y computacionales, que incluyen la propagación hacia adelante, la retropropagación a través del tiempo y la optimización mediante algoritmos como el descenso por gradiente. La propagación hacia adelante permite que las RNN procesen una entrada en cada paso de tiempo y produzcan una salida; sin embargo, uno de los aspectos más desafiantes de este proceso es manejar la desaparición del gradiente, donde las actualizaciones de los pesos pueden volverse infinitesimales en etapas de secuencias largas.
En este sentido, tecnologías adicionales como las redes neuronales recurrentes de tipo LSTM (Long Short-Term Memory) han sido desarrolladas para mitigar este problema. Las LSTM utilizan celdas de memoria que pueden mantener información durante periodos más prolongados, lo que las convierte en una herramienta potente para el análisis de secuencias en bioinformática. Con su arquitectura compleja, estas redes pueden olvidar información irrelevante y retener la significativa, lo que resulta fundamental al analizar la funcionalidad de genes, proteínas y otras biomoléculas.
Aplicaciones de las redes neuronales recurrentes en bioinformática
Las aplicaciones de las RNN en bioinformática son diversas y abarcan varias áreas clave. Una de las aplicaciones más notables es en el análisis de secuencias de ADN y ARN. Las RNN pueden ser entrenadas para identificar patrones en las secuencias que podrían indicar la presencia de elementos reguladores, mutaciones asociadas a enfermedades o incluso la funcionalidad de genes. Por ejemplo, la predicción de genes en un genoma puede lograrse mediante el uso de una RNN que analice fragmentos de ADN y determine la probabilidad de que un segmento particular sea un gen codificante.
Otra aplicación importante radica en la predicción de la estructura de proteínas. La conformación tridimensional de las proteínas es fundamental para su función, y las RNN, especialmente las LSTM, pueden ser utilizadas para modelar las secuencias de aminoácidos y prever cómo estas secuencias se pliegan en estructuras específicas. Esto tiene implicaciones significativas en la investigación de enfermedades, el desarrollo de medicamentos y la ingeniería de proteínas, donde comprender la relación entre la secuencia y la estructura es esencial.
Beneficios de utilizar RNN en bioinformática
Utilizar redes neuronales recurrentes en el campo de la bioinformática tiene varios beneficios. En primer lugar, su capacidad para procesar información secuencial les permite manejar datos complejos y de alta dimensión de manera efectiva. Esto es especialmente relevante en bioinformática, donde los volúmenes de datos generados son extraordinarios. Por ejemplo, el análisis de datos de secuenciación de nueva generación (NGS) genera enormes cantidades de información que las RNN pueden desglosar y analizar para obtener insights significativos.
Además, las RNN permiten abordar problemas que de otro modo serían difíciles de resolver con enfoques computacionales tradicionales. Su capacidad para adaptarse y aprender de los datos hace que sean altamente efectivas en la identificación de patrones no evidentes y en la predicción de resultados en situaciones complejas, como la modelación de interacciones biomoleculares. Esto ha llevado a avances en áreas como la farmacogenómica, donde las RNN ayudan a predecir la respuesta de un paciente a un tratamiento basándose en su perfil genético único.
Desafíos y limitaciones de las RNN en bioinformática
A pesar de sus numerosas ventajas, el uso de redes neuronales recurrentes en bioinformática también presenta desafíos significativos. Uno de los principales problemas es el overfitting, donde el modelo se ajusta demasiado a los datos de entrenamiento y pierde su capacidad de generalización a conjuntos de datos nuevos. Esto puede ser especialmente problemático con conjuntos de datos biológicos que a menudo son ruidosos y escasos.
Otro desafío es el tiempo de entrenamiento de las RNN, que puede ser considerablemente largo, especialmente cuando se trabajan con grandes conjuntos de datos y arquitecturas complejas como las LSTM. La optimización de estos modelos requiere una cuidadosa selección de parámetros y un potente hardware de computación, lo que puede ser limitante para algunos investigadores y organizaciones. Además, la interpretación de los resultados construidos por las RNN puede ser compleja, lo que desafía a los científicos a entender los mecanismos biológicos subyacentes a las salidas del modelo.
El futuro de las RNN en bioinformática
El futuro del uso de redes neuronales recurrentes en bioinformática parece prometedor, con avances continuos en algoritmos y arquitecturas que mejoran la precisión y la eficiencia de estos modelos. Con el aumento en la disponibilidad de datos biológicos a través de tecnologías como la secuenciación de ADN y la biología sintética, las RNN están bien posicionadas para jugar un papel crucial en la interpretación y análisis de estos datos complejos.
La integración de las RNN con otras técnicas de inteligencia artificial, como el aprendizaje reforzado y las redes adversariales generativas, también abre nuevas oportunidades en el campo. Estas combinaciones pueden facilitar la identificación de nuevos biomarcadores, la personalización de tratamientos y una mejor comprensión de la biología subyacente de las enfermedades. En particular, la capacidad de las RNN para realizar predicciones precisas y aprender de grandes volúmenes de datos puede llevar a descubrimientos revolucionarios en la medicina de precisión.
Conclusión
Las redes neuronales recurrentes representan un avance significativo en el análisis y la interpretación de datos biológicos en el campo de la bioinformática. Su capacidad para procesar información secuencial las convierte en herramientas valiosas para abordar problemas complejos relacionados con el ADN, ARN y proteínas. A medida que continuemos desarrollando y refinando estas tecnologías, es probable que veamos un aumento en su aplicación y eficacia, con potencial para transformar áreas de investigación y atención médica.
Sin embargo, es fundamental abordar los desafíos actuales, como el overfitting y la interpretación de modelos, para maximizar su impacto. El uso de RNN en bioinformática no solo está cambiando la forma en que procesamos y analizamos datos biológicos, sino que también nos ofrece nuevas posibilidades en la comprensión de la vida a nivel molecular, allanando el camino para futuras innovaciones en la ciencia y la medicina.
Si quieres conocer otros artículos parecidos a Uso de redes neuronales recurrentes en bioinformática puedes visitar la categoría Machine Learning.
Metodologías para la recolección de datos biológicos eficaces

Cómo se aplica el Machine Learning a la genética

El futuro de la salud: el papel de la inteligencia artificial

Análisis de series temporales en datos biológicos: Qué es

Uso de Machine Learning en el descubrimiento de fármacos

Bioaprendizaje: fundamentos y aplicaciones en ML y IA
Deja una respuesta