
ANOVA en bioinformática: guía paso a paso para su uso
El análisis de varianza, comúnmente conocido como ANOVA, es una técnica estadística fundamental en numerosos campos, incluida la bioinformática. Su propósito principal es determinar si existen diferencias significativas entre las medias de tres o más grupos. En la vastedad de datos biológicos, desde la expresión genética hasta las medidas fenotípicas, la capacidad de discernir diferencias significativas es esencial para la interpretación y validación científica. Los investigadores cuentan con un sofisticado conjunto de herramientas para analizar estos datos complejos y el ANOVA se erige como una opción primordial.
En este artículo, exploraremos en profundidad el ANOVA y su aplicación en la bioinformática, a través de una guía paso a paso que cubre los conceptos. Desde las bases teóricas del análisis de varianza hasta su implementación práctica, nos aseguraremos de que comprendas no solo cómo se utiliza esta técnica, sino también por qué es vital en el análisis de datos biológicos. A medida que avancemos, desglosaremos los diferentes tipos de ANOVA, los supuestos que deben cumplirse, así como ejemplos prácticos que clarificarán su uso en contextos bioinformáticos.
Índice
¿Qué es el ANOVA y cómo funciona?
El término ANOVA, que proviene de las palabras en inglés "Analysis of Variance", se traduce literalmente como análisis de varianza. Su finalidad es comparar las medias de diferentes grupos para determinar si por lo menos uno de ellos es significativamente diferente de los demás. El método se basa en la descomposición de la varianza de los datos en componentes que se pueden atribuir a diferentes fuentes.
Para llevar a cabo un análisis de varianza, se parte de la hipótesis nula que establece que no hay diferencias significativas entre las medias de los grupos analizados. A partir de ahí, el ANOVA calcula la varianza dentro de cada grupo y la varianza entre los grupos. La relación de estas dos varianzas se utiliza para calcular el estadístico F, que es fundamental para evaluar si se puede rechazar la hipótesis nula en función de un nivel de significancia preestablecido.
Tipos de ANOVA en bioinformática
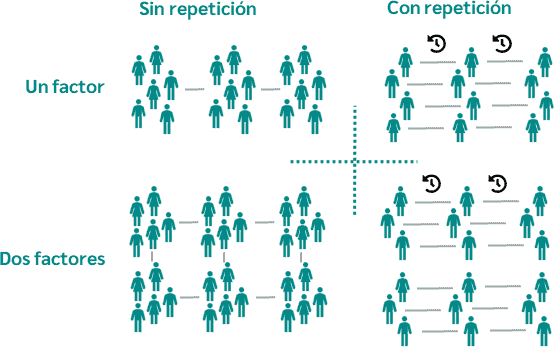
Dentro del contexto del ANOVA, existen varios tipos que se aplican en la bioinformática, cada uno adaptándose a diferentes situaciones experimentales. Los más relevantes son el ANOVA de un solo factor, ANOVA de dos factores, y el ANOVA de medidas repetidas. El ANOVA de un solo factor se utiliza cuando se desea evaluar la diferencia en la media entre tres o más grupos que están categorizados por una sola variable independiente. Por ejemplo, podría aplicarse para evaluar la expresión génica en diferentes tratamientos de células.
Por otro lado, el ANOVA de dos factores es útil cuando se incluye más de una variable independiente en el análisis. Esto permite observar no solo las diferencias causadas por cada variable, sino también las interacciones entre ellas. Esta técnica puede ser particularmente beneficiosa en experimentos complejos donde las interacciones son relevantes, como en estudios que examinan el efecto combinado de la dieta y la genética en el fenotipo de una población.
Finalmente, el ANOVA de medidas repetidas se aplica cuando las mismas muestras se miden en diferentes condiciones o en diferentes momentos. Es esencial en el análisis de datos longitudinales, como en estudios donde se analizan los efectos de un tratamiento en varios momentos en la misma serie de experimentos.
Supuestos del ANOVA
Antes de realizar un análisis de varianza, es fundamental asegurarse de que los datos cumplen con ciertos supuestos. Estos incluyen la normalidad, la homogeneidad de varianzas y la independencia de las observaciones. La normalidad asume que los datos provenientes de cada grupo se distribuyen normalmente. Esto se puede verificar mediante pruebas como la prueba de Shapiro-Wilk o visualizando gráficos de probabilidad normal.
El segundo supuesto, la homogeneidad de varianzas, implica que las varianzas de los distintos grupos deben ser aproximadamente iguales. Una prueba común para evaluar este supuesto es la prueba de Levene. Si estos supuestos no se cumplen, los resultados del ANOVA pueden ser poco fiables. En tales casos, se pueden optar por transformaciones de datos o considerar métodos alternativos, como el uso de ANOVA no paramétrico.
Ejemplo práctico de ANOVA en bioinformática
Ahora que hemos abordado los fundamentos del ANOVA, es crucial ilustrarlo con un ejemplo práctico en bioinformática. Imaginemos un estudio que explora el efecto de diferentes tratamientos sobre la expresión de un gen específico en células madre. Supongamos que tenemos tres grupos: un grupo de control y dos grupos que reciben diferentes tratamientos.
Al final del experimento, se mide la expresión génica en todos los grupos y se recogen los datos. Para analizar estos datos, primero se realiza un gráfico descriptivo para visualizar las diferencias de expresión entre los grupos. Luego, se ejecuta un ANOVA de un solo factor para determinar si hay diferencias estadísticamente significativas en la expresión génica entre los diferentes tratamientos. Si se obtiene un valor de p menor que el nivel de significancia (generalmente 0.05), se rechaza la hipótesis nula, indicando que al menos un grupo es significativamente diferente de los demás.
Finalmente, para identificar qué grupos son diferentes entre sí, se podría realizar un análisis post hoc, como el test de Tukey. Este paso es esencial, ya que el ANOVA solo indica si existe una diferencia entre los grupos, pero no identifica específicamente dónde se encuentran esas diferencias.
Conclusión
El uso del ANOVA en bioinformática es vital para comparar múltiples grupos y determinar diferencias significativas en datos extensos y complejos. A través de esta guía, hemos explorado los distintos tipos de ANOVA, los supuestos que subyacen a su implementación, y cómo puede aplicarse en un contexto práctico. Entender el ANOVA no solo ayuda a los investigadores a analizar los datos de manera eficaz, sino que también permite realizar inferencias que son esenciales para el avance del conocimiento en biología y campos relacionados.
A medida que la bioinformática sigue evolucionando y los datos siguen creciendo en complejidad y volumen, el ANOVA se mantiene como una herramienta imprescindible para los bioinformáticos y biólogos experimentales. Su capacidad para revelar la varianza y las relaciones entre datos biológicos seguirá siendo un componente crucial en el análisis y la interpretación de investigaciones en el ámbito de la biología.
Si quieres conocer otros artículos parecidos a ANOVA en bioinformática: guía paso a paso para su uso puedes visitar la categoría Estadística.
Precisión y fiabilidad en bioinformática: técnicas y usos

Método de Máxima Verosimilitud: Definición y Aplicaciones

Métodos estadísticos más comunes en bioinformática

Qué es el análisis de correspondencia y su aplicación

Datos ómicos: definición y análisis estadístico esencial
Estimaciones en estudios de caso-control: Cómo se realizan
Deja una respuesta