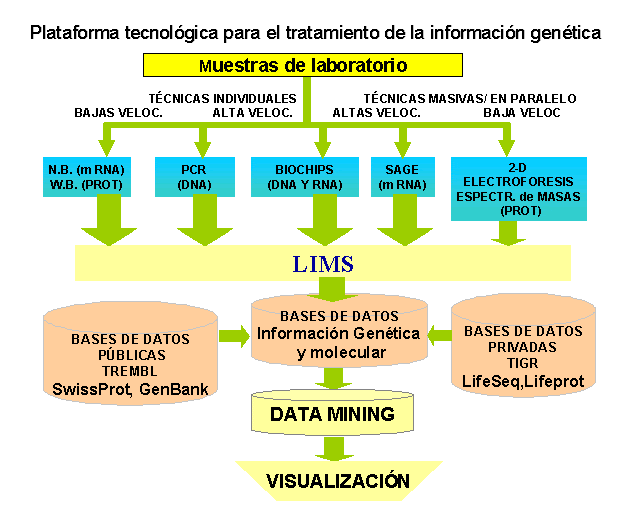
Uso de herramientas de machine learning en bioinformática

La intersección entre machine learning y bioinformática está revolucionando la forma en que los científicos comprenden y manipulan datos biológicos. La creciente complejidad de estos datos, desde la secuenciación del ADN hasta el análisis de proteínas, ha llevado a la búsqueda de herramientas más sofisticadas que puedan extraer patrones y conocimientos útiles de grandes volúmenes de información. Este enfoque no solo optimiza el análisis biológico, sino que también abre nuevas avenidas en la investigación biomédica, la farmacología y la genética.
En este artículo, exploraremos cómo se están utilizando las herramientas de machine learning en diversos campos de la bioinformática. Abordaremos sus aplicaciones, los avances más significativos y los desafíos que enfrenta esta disciplina a medida que se infiltra cada vez más en la atención médica y la investigación biológica. A través de un análisis exhaustivo de estas herramientas y técnicas, brindaremos una visión completa de cómo están moldeando el futuro de la ciencia de datos biológicos.
Índice
Introducción al Machine Learning en Bioinformática
El machine learning, o aprendizaje automático, es una rama de la inteligencia artificial que permite a las computadoras aprender de los datos sin ser programadas explícitamente. En bioinformática, esta capacidad es especialmente valiosa, dado el volumen y la complejidad de los datos biológicos generados. Desde la composición genética de los organismos hasta las interacciones entre proteínas, el machine learning ofrece métodos para modelar y predecir comportamientos biológicos basados en grandes conjuntos de datos.
Una de las áreas donde el machine learning ha tenido un impacto significativo es en el análisis de secuencias genéticas. Técnicas como el aprendizaje profundo y los algoritmos de clasificación pueden identificar patrones en las secuencias de ADN, lo que lleva a descubrimientos en genética y medicina personalizada. Así, el machine learning se convierte en una herramienta crucial para desentrañar la complejidad de los sistemas biológicos, permitiendo a los investigadores hacer predicciones sobre la función de genes específicos y sus implicaciones en enfermedades.
Aplicaciones de Machine Learning en Genómica
La genómica es una de las áreas más dinámicas dentro de la bioinformática, y la implementación de técnicas de machine learning ha permitido avances sin precedentes en nuestro entendimiento del genoma. Por ejemplo, el análisis de variantes genéticas, que busca identificar mutaciones o polimorfismos, se ha beneficiado enormemente de algoritmos que pueden discriminar entre variantes benignas y patogénicas. Algoritmos como los árboles de decisión y las redes neuronales son utilizados para clasificar estas variantes, lo que ayuda en el diagnóstico de enfermedades genéticas.
Un estudio reciente aplicó un modelo de machine learning a datos de secuenciación de nueva generación (NGS), lo que permitió a los investigadores detectar mutaciones en tumores con una precisión superior a la de los métodos tradicionales. Esta capacidad de identificar con precisión las alteraciones genéticas en el ADN tumoral ha llevado a un avance en el desarrollo de terapias dirigidas, personalizando los tratamientos según el perfil genético del paciente.
Machine Learning en Proteómica
Al igual que en la genómica, el machine learning también ofrece oportunidades únicas en la Proteómica, el estudio de las proteínas y sus funciones. A través de técnicas de aprendizaje automático, se pueden predecir estructuras y funciones de proteínas basándose en su secuencia aminoacídica. Los modelos pueden identificar interacciones entre proteínas y predecir efectos de modificaciones post-traduccionales. En un mundo donde las proteínas desempeñan papeles vitales en casi todos los procesos biológicos, esta capacidad es invaluable.
El uso de algoritmos de machine learning ha facilitado el desarrollo de bases de datos que contiene información sobre interacciones proteína-proteína, lo que es esencial para entender rutas metabólicas y mecanismos de enfermedades. Estos modelos permiten a los científicos analizar grandes cantidades de datos proteómicos para descubrir nuevas biomarcadores, facilitando el diagnóstico y el tratamiento de enfermedades a nivel molecular.
Machine Learning y Medicina Personalizada
La medicina personalizada es un área que se está expandiendo de manera significativa gracias al machine learning. Al analizar datos genómicos junto con información clínica, es posible desarrollar tratamientos que se adapten a las características individuales de cada paciente. Los modelos predictivos pueden evaluar la eficacia de las terapias basándose en los antecedentes genéticos y la composición molecular del paciente.
Por ejemplo, el análisis de datos provenientes de ensayos clínicos y registros médicos permite a los investigadores utilizar machine learning para identificar qué pacientes tienen más probabilidades de responder a un tratamiento específico. Esto no solo mejora los resultados de salud, sino que también minimiza el uso de tratamientos ineficaces, optimizando así los recursos en atención médica. Este enfoque está transformando la práctica clínica, haciendo de la personalización un estándar en la atención al paciente.
Desafíos del Machine Learning en Bioinformática
A pesar de los inmensos beneficios que trae el machine learning en bioinformática, también existen diversos desafíos que deben ser abordados. Uno de los principales problemas es la calidad y la cantidad de datos disponibles. Los modelos de machine learning requieren grandes volúmenes de información de alta calidad para ser efectivos, y en el ámbito biológico, la obtención y el manejo de estos datos pueden ser problemáticos.
Además, existe la cuestión de la interpretabilidad de los modelos. Muchos algoritmos de machine learning, especialmente aquellos basados en redes neuronales profundas, son considerados "cajas negras". Esto significa que, aunque pueden ofrecer alta precisión en las predicciones, es difícil interpretar cómo llegaron a esos resultados, lo que plantea desafíos en la validación y aceptación de estos modelos en un contexto clínico.
El Futuro del Machine Learning en Bioinformática
El futuro del machine learning en bioinformática parece prometedor, con continuas innovaciones que impulsan el desarrollo de herramientas más efectivas y robustas. Con el avance de la tecnología y la generación de más datos biológicos, los modelos de aprendizaje automático se volverán cada vez más sofisticados. A medida que los científicos abordan la interpretación de los modelos y se preocupan por la calidad de los datos, se espera que el uso de estas técnicas se expanda aún más.
La colaboración interdisciplinaria entre biólogos, informáticos y médicos será crítica para maximizar el potencial del machine learning en la bioinformática. Al combinar conocimientos y habilidades de diferentes sectores, será posible crear un marco completo que no solo permita aprovechar los datos biológicos, sino que también potencie la investigación biomédica en nuevas direcciones.
Conclusiones
El uso de herramientas de machine learning en bioinformática representa un avance crucial en el análisis de datos biológicos complejos. Desde la genómica hasta la proteómica y la medicina personalizada, estas herramientas están cambiando la manera en la que los investigadores abordan problemas biomédicos, ofreciendo precisión y eficiencia. Sin embargo, enfrentan desafíos significativos que deben ser enfrentados para lograr una integración exitosa en la práctica clínica. El futuro es brillante, y a medida que continuamos explorando este fascinante campo, el potencial para revolucionar la ciencia de la vida y mejorar la atención al paciente es inmenso.
Si quieres conocer otros artículos parecidos a Uso de herramientas de machine learning en bioinformática puedes visitar la categoría Herramientas.
Validación de resultados en estudios bioinformáticos: métodos y enfoques

Guía completa para usar BLAST eficientemente en bioinformática
Softwares de preprocesamiento de datos biológicos: qué son

Selección de un lenguaje de programación para bioinformática

Herramientas clave para realizar metaanálisis en bioinformática

Herramientas clave para el análisis de variantes genéticas
Deja una respuesta